How to build a CI/CD workflow with Skaffold for your application (Part II)
Using Gitlab, K8s, Kustomize and a Symfony PHP application with RoadRunner

🔥 This is the second part of the series "Full CI/CD workflow with Skaffold for your application".
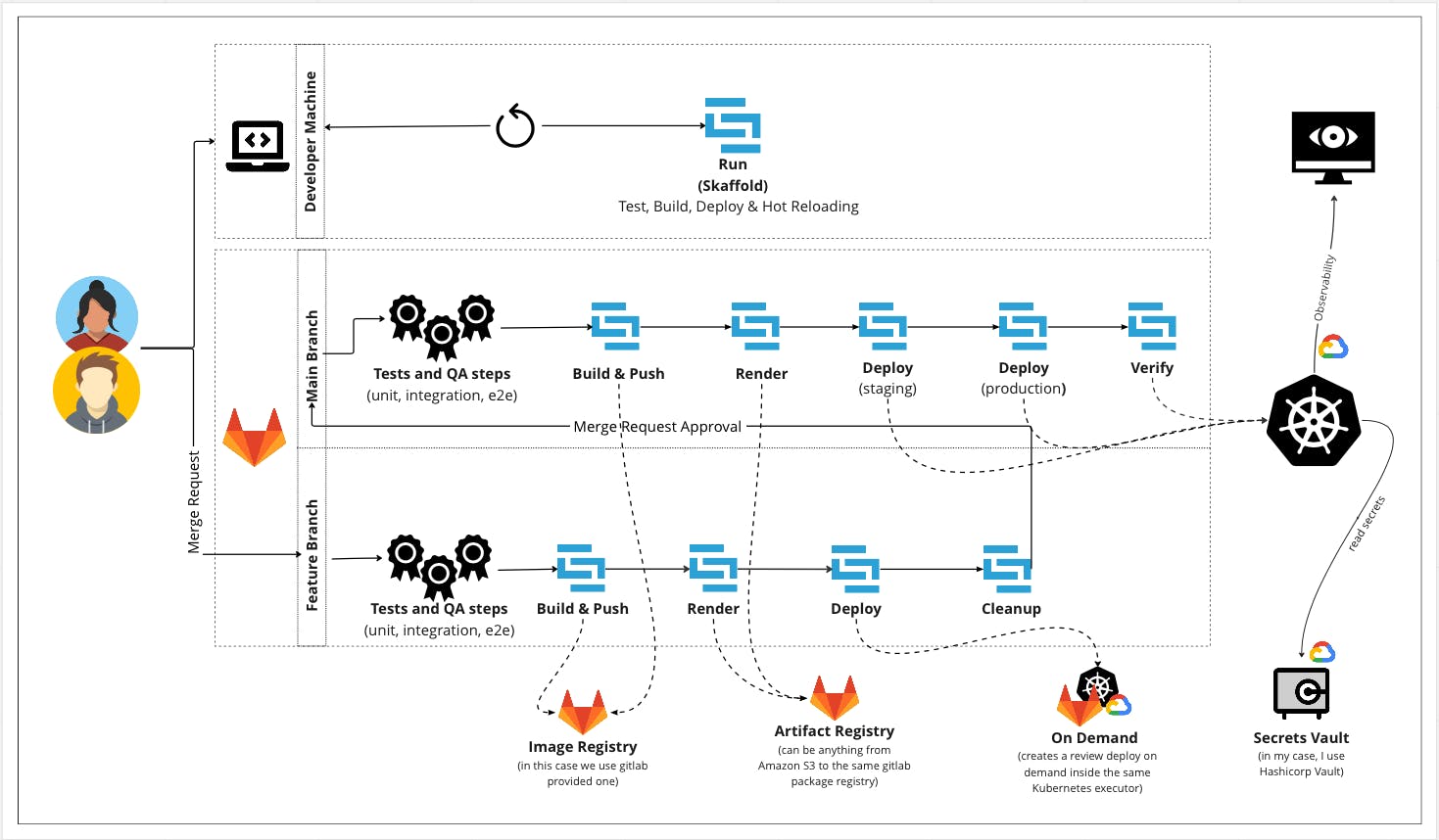
Lets recap the Workflow
As you remind - and if not, you can read the first release of this tutorial 😅 - my main idea is to implement one tool - skaffold - as a building block for my CI/CD workflow, who should be managed by a single makefile as entrypoint for local development and pipelines - on gitlab - and all this should be deployed in a K8s cluster in GCP
And also, for the simplicity of this tutorial, we use the image and artefact repository in the same gitlab SAAS, but you can use whatever you want for this task (Amazon S3, Docker Registry, Private Registries, Azure Object Storage, etc)
This is the workflow so far:
📣 The tool setup and local workflow were covered in the first delivery of this tutorial.
The Makefile
As said, the makefile, is, the main entrypoint for commands to be executed by developers when they do development work locally, and for gitlab pipelines in their different stages (must vary on your implementation), and that makefile commands mostly are wraps for skaffold ones, with the difference, that i need to pass dynamic values to those stages to work I expect to, so it's better to wrap then in a makefile target that received that dynamic params and then run the 'skaffold' command itself. (later you will now why)
As for the time I was writing this article, my targets are:
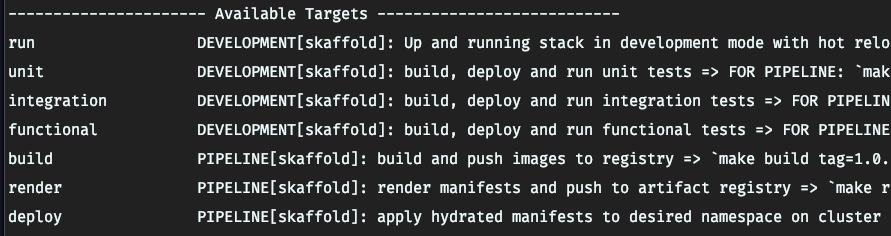
Hopefully for local development we have an unique command since skaffold run do the full pipeline cycle (build, test, deploy, hot reload) for development , so, why then i need to wrap this single command in a makefile target?, mostly because I need that this work no matter what type/kind of local cluster technology the developer use (docker-desktop, Minikube, etc) and no matter what OS developer machine was (MacOS, *Nix) and for that, I need to pass the kube-context parameter to skaffold that in my case is docker-desktop (since docker desktop already bring me a pre installed k8s cluster for local development and that free me to the need to install manually a cluster in my machine - a win for docker-desktop here -.
So you will encounter that the majority of the makefile wraps, come in the form of rehuse the same command in multiple stages (pipelines) based on the received parameter in the make execution, and also, generating random seeds to prefix namespaces (because you will have more than one developer working in the same code base at once) and I want to avoid collision between gitlab pipelines and deploys in lower environments when N developers are working in the same code base.
We must focused in pipeline target ones (all of then with skaffold tool), since the infrastructure ones, related to install prerequisites in local cluster to comply with the architecture design, isn't cover in this series, but in the another series that 'll wrote in next weeks)
Here is how my makefile looks at the time of writing this article, and for those stages (because in technology everything evolves quickly I always remind this 😅)
#------ Development and Pipeline targets ----------#
run: ## DEVELOPMENT[skaffold]: Up and running stack in development mode with hot reloading in the local machine
@$(MAKE) _requirements
@skaffold dev -f $(DEPLOY_DIR)/skaffold.yaml -p development -n $(PROJECT_NAME) --no-prune=false --cache-artifacts=false
unit: ## DEVELOPMENT[skaffold]: build, deploy and run unit tests => FOR PIPELINE: `make unit profile=pipeline kube_context=cluster-gitlab-context`
@$(MAKE) _run_test_suite SUITE=unit PROFILE=$(PROFILE) NAMESPACE=$(DYNAMIC_NAMESPACE) KUBE_CONTEXT=$(KUBE_CONTEXT) || $(MAKE) _cleanup KUBE_CONTEXT=$(KUBE_CONTEXT) PROFILE=$(profile) NAMESPACE=$(DYNAMIC_NAMESPACE)
integration: ## DEVELOPMENT[skaffold]: build, deploy and run integration tests => FOR PIPELINE: `make integration profile=pipeline kube_context=cluster-gitlab-context`
@$(MAKE) _run_test_suite SUITE=integration PROFILE=$(PROFILE) NAMESPACE=$(DYNAMIC_NAMESPACE) KUBE_CONTEXT=$(KUBE_CONTEXT) || $(MAKE) _cleanup KUBE_CONTEXT=$(KUBE_CONTEXT) PROFILE=$(profile) NAMESPACE=$(DYNAMIC_NAMESPACE)
functional: ## DEVELOPMENT[skaffold]: build, deploy and run functional tests => FOR PIPELINE: `make functional profile=pipeline kube_context=cluster-gitlab-context`
@$(MAKE) _run_test_suite SUITE=functional PROFILE=$(PROFILE) NAMESPACE=$(DYNAMIC_NAMESPACE) KUBE_CONTEXT=$(KUBE_CONTEXT) || $(MAKE) _cleanup KUBE_CONTEXT=$(KUBE_CONTEXT) PROFILE=$(profile) NAMESPACE=$(DYNAMIC_NAMESPACE)
build: ## PIPELINE[skaffold]: build and push images to registry => `make build tag=1.0.0|71dcab00 kube_context=docker-desktop`
@skaffold build -f $(DEPLOY_DIR)/skaffold.yaml -p production -t $(tag) --kube-context=$(kube_context) --file-output=pipeline-artifacts.json
render: ## PIPELINE[skaffold]: render manifests and push to artifact registry => `make render namespace=availability tag=1.0.0|71dcab00`
@skaffold render -f $(DEPLOY_DIR)/skaffold.yaml -p production -n $(PROJECT_NAME) -a pipeline-artifacts.json -o $(PROJECT_NAME)-api-$(tag)-production.yaml
deploy: ## PIPELINE[skaffold]: apply hydrated manifests to desired namespace on cluster `make deploy tag=1.0.0|71dcab00 profile=production namespace=availability kube_context=docker-desktop`
@kubectl create namespace $(namespace) --context=$(kube_context)
@skaffold apply -f $(DEPLOY_DIR)/skaffold.yaml -p $(profile) -n $(namespace) --kube-context=$(kube_context) --status-check=true $(PROJECT_NAME)-api-$(tag)-production.yaml || $(MAKE) _cleanup KUBE_CONTEXT=$(kube_context) PROFILE=$(profile) NAMESPACE=$(namespace)
As you can see, all targets are warps for skaffold, but, allowing me to pass dynamic data, context and profiles (we'll look this in the skaffold file explanation below), the complete file is more larger, but with this snippet you can get an idea on how you can build something like that.
The skaffold file
The main workflow orchestrator has a main config file, when we can define, how the application should be builded, tested, render their manifest and deployed, so it's a vertebral part of this strategy, and now I'll explain you mine.
I have two skaffold profiles: one called development and the other production, and a common part share between them like tag strategy, deploy strategy, and both of them use the same Dockerfileto build their images pointing to the correcttarget`. (You can use separate Dockerfiles, but in my case I want to maintain as simple as possible because the difference between 2 images dependencies are minimum)
the skaffold fiel lives inside my deploy folder (do you remember my file organisation? You can re-checked in the first delivery of this series), and all the deployment related files are store there.
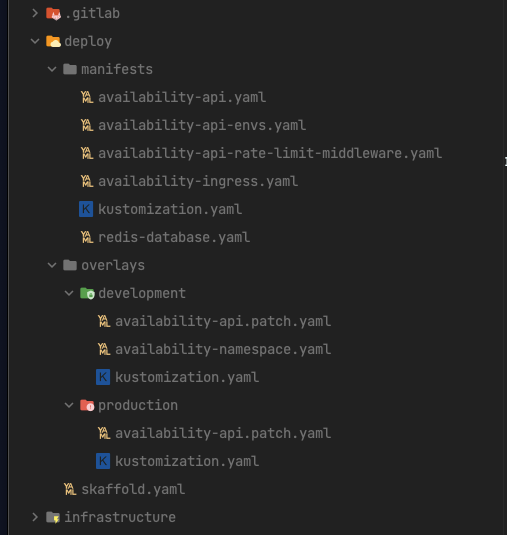
As you can see the skaffold.yaml file is in the root of the deploy folder since is my main workflow orchestrator, in the other folder we have the main k8s manifests and inside overlays we have the yaml patch's for every profile (most of the cases the same as an environment) that we want to declare.
The .gitlab-ci.yml Pipeline
Since I use trunk base development strategy in micro services, we need to design 2 flows of pipelines, one for features branches and one for main branch, additionally to that, to be able to reach production we first need to tag a commit, so that's the real trigger for Go-To-Prod Pipeline.
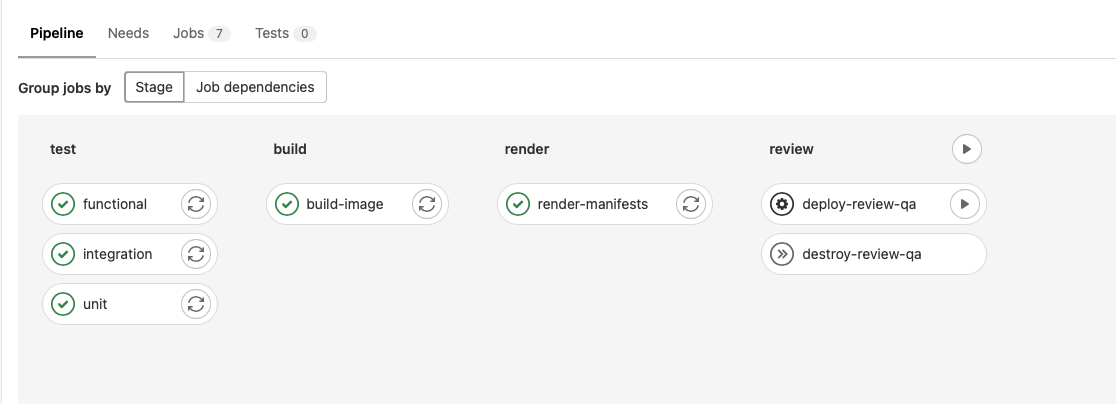
Feature Branches Workflow (trigger by merge_request commit):
In this stage, the developer needs to be able to:
Run all tests suites
Build and Image with production dependencies
Deploy to a dynamic namespace in the same cluster where pipeline runs (a Dynamic QA to say so, allowing to every developer to have "their own" QA server while their are working on a feature)
Destroy the dynamic deployment (remove review app and namespace)
Looks like this:
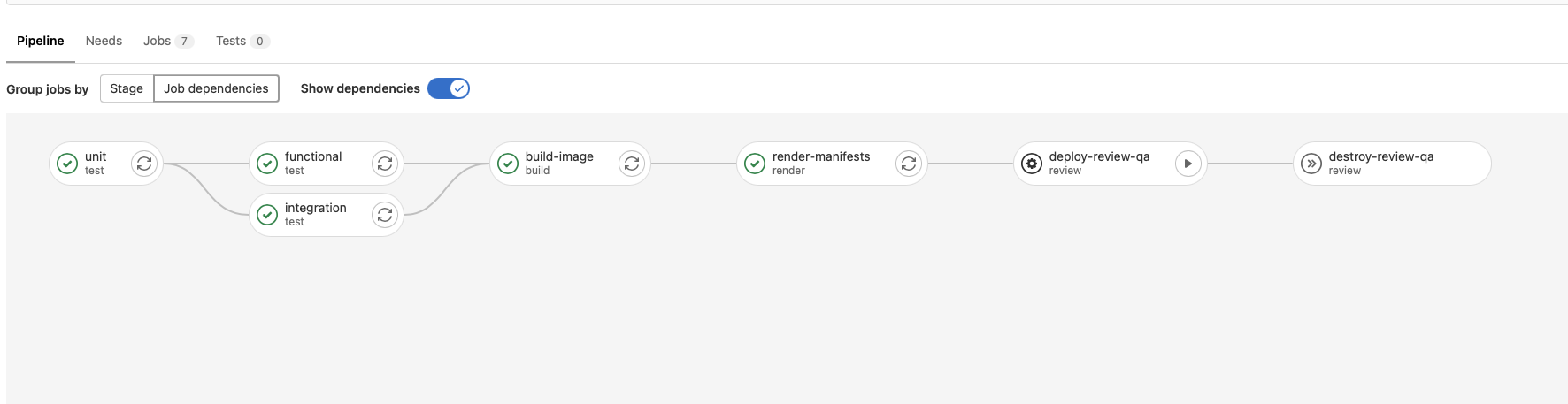
Also we use gitlab environments to see in the Gitlab UI "what's is deployed in what environment", and also to visualise production and stages latest deployment status and artefacts.
So, when a new "dynamic QA" environment is deployed, you'll see this in environment page of your project:
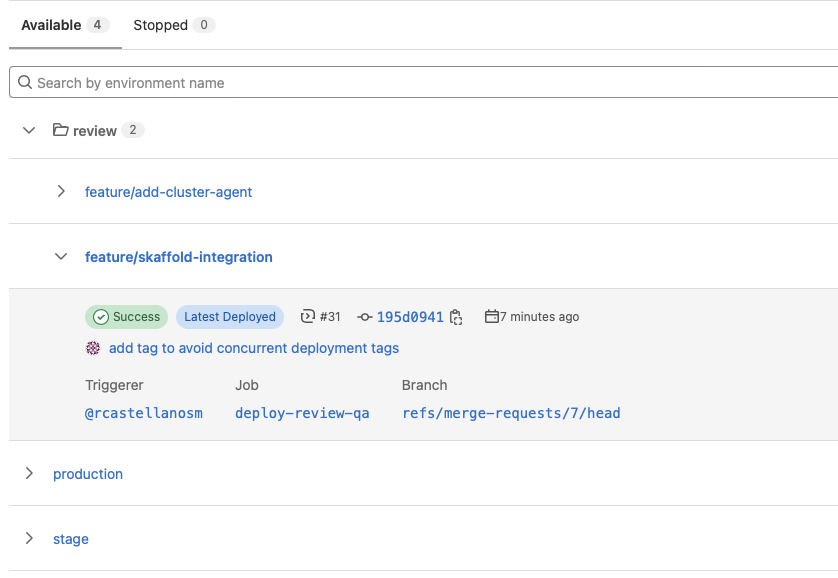
And also on the MR View on Gitlab you'll see in what "review" environment is deployed that MR.
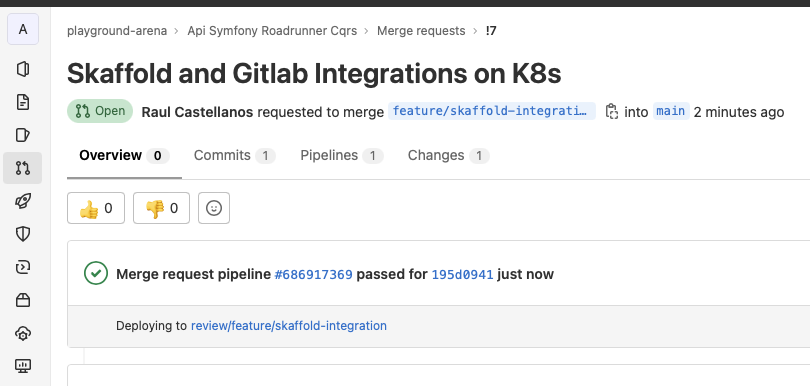
Main Branch Workflow (trigger by a TAG):
In this stage, the developer needs to be able to:
Run all tests suites
Build and Image with production dependencies
Create a Release Package (this a gitlab feature like Github to display release contents in a special page on gitlab)
Deploy to Production
Looks like this:
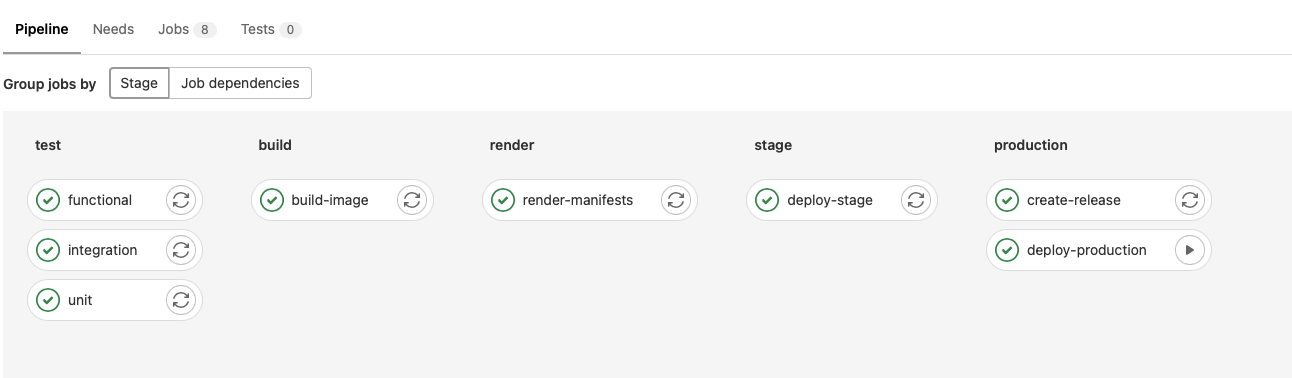
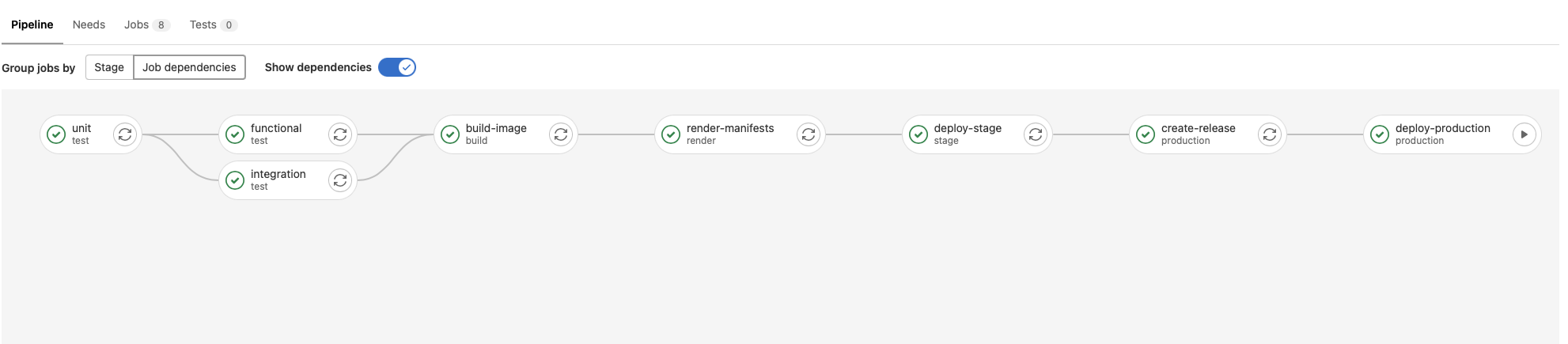
The main workflow has 3 stages more, including deploying to staging cluster/namespace, but more important has the creation of the release package and the deployment to production.
The only manual job is deploy to production.
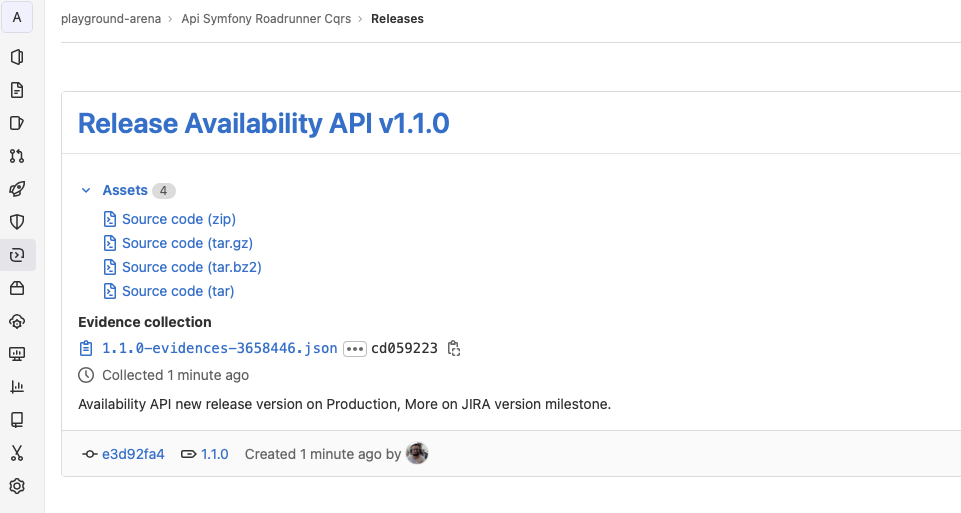
Gitlab Release
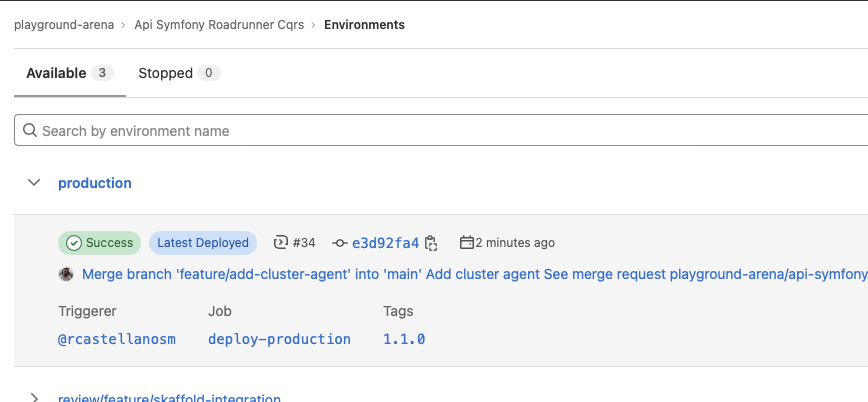
Production Environment after Deployment
All the best of all, all this is DONE automatically via the automated Pipeline on Gitlab. You can view the skeleton of the pipeline in this Snippet:
https://gitlab.com/playground-arena/api-symfony-roadrunner-cqrs/-/snippets/2448780
BONUS: Kaniko image Builder
Since version 1.24, Kubernetes was moving away from dockershim as container runtime, so I want a solution that:
Allow me to build container inside a K8s cluster
Continue to writing Dockerfiles as today
Not need to share or mount a socket into a pod (that's the main security reason to not use docker)
So I discover the last year Kaniko, this is another tool on the Google Container Tools on Github, that allows us to build an container image from a Dockerfile without Docker. Marvellous.
It has som benefits:
*Kaniko doesn't depend on a Docker daemon and executes each command within a Dockerfile completely in userspace. (no need to mount a docker socket anymore)
Provides a handy docker image to use in pipelines (a very light weight one, so your jobs doesn't take much time to run)
Provides a Caching system in the same repository where the images are stored, so in every job that tries to build the image,
Kanikowill check first the repo cache layers and downloaded speeding up the build job.
When a build a image I check my repo and I can see the caching layers separated from the final images (see image below)
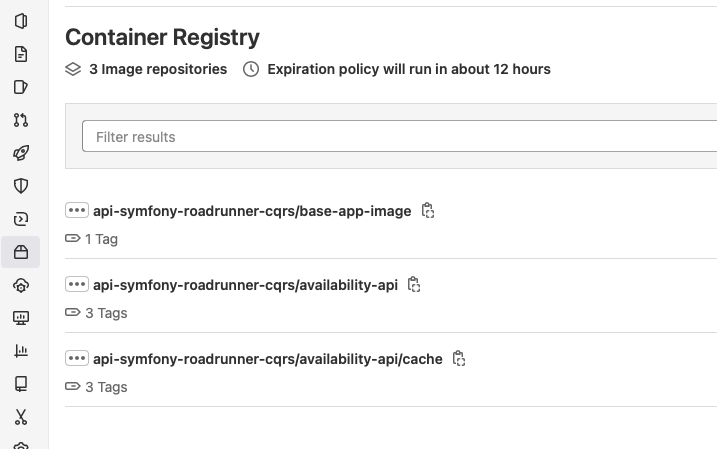
Cache Layers
Builded and Tagged Images
Deployment safety considerations
All in life has it's tradeoff, and this isn't the exception, however, is possible to joint team autonomy with security and governance, no only with this example, but in general in software development.
Some of my personal recommendations on this are:
Secrets: Always use a secret vault (in my case i use Hashicorp one)
Fine-grained permissions control with the CI/CD tunnel via impersonation and k8s agent:
Allows you to leverage your K8s authorization capabilities to limit the permissions of what can be done with the CI/CD tunnel on your running cluster
Lowers the risk of providing unlimited access to your K8s cluster with the CI/CD tunnel
Segments fine-grained permissions with the CI/CD tunnel at the project or group level
Controls permissions with the CI/CD tunnel at the username or service account
Make your high environment namespaces immutable (on K8s namespace creation time)
Fine-Grained RBAC on Gitlab Roles (I think this isn't available on the Free and Self-Managed versions)
Next Chapter
In the next chapter I'll wrap up all things that we cover in the first 2 releases of the series in a fully functional pipeline from local to production with a small k8s cluster and I expect, that you can see all the work in action and some final remarks to allow you to test in your projects.
Thanks for reading!
Support me
If you like what you just read and you find it valuable, then you can buy me a coffee by clicking the link in the image below.



